廉价的K8s LB方案--MetalLB
MetalLB为本地运行的Kubernetes集群提供了LoadBalance功能,使用户像在公有云环境一样,使用K8S的LoadBalancer Service。
在Kubernetes中部署MetalLB后,会有两个部分,一部分是负责监听K8S Service资源变化的Controller,以Deployment的方式部署在整个集群上,另一部分是各个节点上的代理组件Speaker,以DaemonSet方式部署,负责ARP Reply或是BGP的宣告。
MetalLB有两种模式,一种是二层网络模式,一种是BGP模式。
二层网络模式
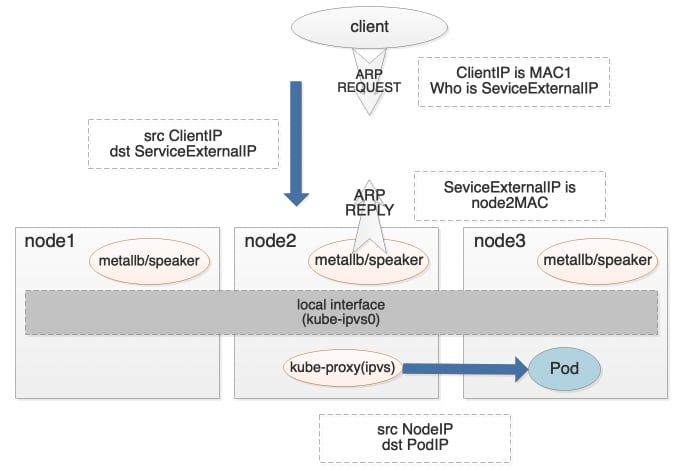
二层网络模式,顾名思义,所有的流量都在一个二层网络中。此模式下MetalLB其实并未进行负载均衡,而是借助其他组件例如Kube-proxy,来实现负载均衡。具体的,如上图所示,MetalLB将Service External IP(由MetalLB的Controller根据预先设定好的IP段,配置在LoadBalance类型的Service上)配置在K8S集群节点的local网卡上(比如kube-ipvs0),当Client访问Service External IP时,由于在同一个二层,会广播ARP请求,MetalLB会使用某个节点进行ARP Reply(IPv6通过NDP协议),从而Client请求流量会发送到此节点,然后由节点上的Kube-proxy进行负载,转到真正的Pod地址。
需要说明的是:
1)Service External IP地址需要与Client在同一网段。
2)为了使其他节点不对local网卡上的Service External IP进行ARP Reply,节点需要设置arp_ignore=1以及arp_announce=2,或者是设置Kube-proxy的--ipvs-strict-arp参数。
3)MetalLB对于每个Service会选一个节点,始终由这个节点进行ARP Reply。节点的选择方式是:先过滤出Service后端Pod所在的节点,然后以Service Name、Service Namespace、NodeIP等计算hash值,排序hash值取第一个。
3)由于上面的选择方式,MetalLB对ExternalTrafficPolicy=Local的Service是支持的,但会导致只用到部分后端Pod实例。
4)Kube-proxy会同时进行DNAT与SNAT,回包并不是如LVS DR模式,而是原路返回。
5)Kube-proxy也可以使用其他组件代替,比如Cilium的Kube-proxy replace方案。
二层网络模式在生产环境中使用有限,原因有二:
1)扩展性有限。受ARP协议和NDP协议的限制,每个Service都只有一个真正的“入口”,因此这个节点很可能会成为网络瓶颈的所在。
2)故障转移依赖客户端。MetalLB使用memberlist做为分布式节点的管理,如果当前使用的节点出现故障时,MetalLB会在新的memberlist中(已删除故障节点)再次选择某个节点进行替换。接着MetalLB会给客户端发送一个“额外的二层包”,告知客户端OS需要更新他们的MAC缓存,而在客户端OS更新缓存前,流量仍会转发到故障节点。因此从某种程度来说,故障转移的时间,就依赖于客户端OS更新MAC缓存的速度。
3)选节点的hash并非一致性,添加节点有一定概率导致Service的节点发生变化。
BGP模式
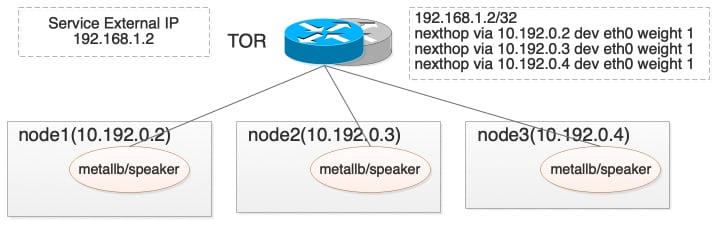
BGP模式不限于一个二层网络里,各个节点都会与交换机建立BGP Peer,宣告Service External IP的下一跳为自身,这样通过ECMP实现了一层负载。客户端请求通过交换机负载到后端某个节点后,再由Kube-proxy进行转发。
对于externalTrafficPolicy=Local的Service,只有本机存在服务Pod时,才会进行Service External IP的BGP路由宣告。
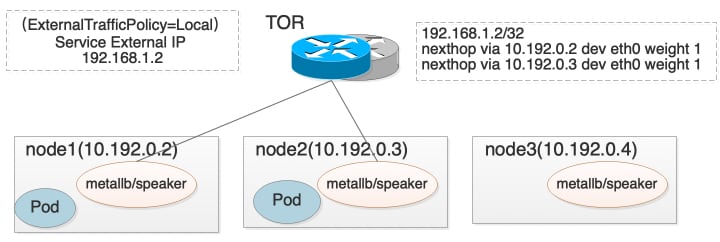
可以看到这种方式实际上是经过了两层的转发,当Service ExternalTrafficPolicy为Cluster时,每次转发的概率其实是均等的,但当Service ExternalTrafficPolicy为Local时,虽然转发到每个节点的概率是一致的,但每个节点上服务Pod数量不一致,导致每个Pod上的流量其实并不均等。
在这种模式中,我们希望对于客户端请求的转发遵循会话保持,否则会出现数据包的乱序或丢弃。一般在硬件上,通过对数据包的3元组(源地址、目标地址、协议)或是五元组(三元组加上源端口、目标端口)进行hash,来实现同一会话转发到相同的后端。但需要注意,这种hash一般不是一致性hash,这就导致当后端某个节点的失效后,会对其他连接也会参数影响,扩大了故障的“爆炸半径”。
官方给了一些缓解的办法,比如在MetalLB和Service后端之间,加入一层有状态的负载——ingress Controller。
另外 ,BGP模式下,MetalLB提供了部分参数,来实现对BGP协议的控制,比如BGP community、localpref等。
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
peers:
- peer-address: 10.0.0.1
peer-asn: 64501
my-asn: 64500
address-pools:
- name: default
protocol: bgp
addresses:
- 198.51.100.0/24
bgp-advertisements:
- aggregation-length: 32
localpref: 100
communities:
- no-advertise
- aggregation-length: 24
bgp-communities:
no-advertise: 65535:65282类比Calico对Service的BGP
从Calico v3.4开始,Calico支持对K8S的Service地址进行BGP,其逻辑和MetalLB BGP逻辑基本相同。有几点区别:
1)默认的情况下,MetalLB是对单个IP进行BGP的,子网掩码是32,但对Calico配置的是一个CIDR,Calico对外BGP的是整个网络段的路由,只有在externalTrafficPolicy为Local时,才会对单个IP进行BGP。
2)Calico不仅会BGP Service External IP,还可以BGP Service ClusterIP,两者的转发过程是类似的,都是将流量负载到某个K8S节点后,进行SNAT与DNAT。
3)Calico不负责LoadBalancer Service IP的分配。
IP地址共享
默认情况下,MetalLB只会将一个IP地址分配到一个LoadBalancer Service上,用户可以通过spec.loadBalancerIP来指定自己想用的IP,如果用户指定了已被分配了的IP会,则会报错。但MetalLB也提供了方式去支持多个Service共享相同的IP,主要为了解决:K8S不支持对LoadBalancer Service中的Port指定多协议;有限的IP地址资源。
具体的方式是:创建两个Service,并加上metallb.universe.tf/allow-shared-ip为Key的annotation,表明Service能容忍使用共享的LoadBalancerIP;然后通过spec.loadBalancerIP给两个Service指定共享的IP。
IP地址共享也有限制:
1)两个Service的metallb.universe.tf/allow-shared-ip值是一样的。
2)两个Service的“端口”(带协议)不同,比如tcp/53和udp/53是属于不同的“端口”。
3)两个Service对应的后端Pod要一致,如果不一致,那么他们的externalTrafficPolicy需要都是Cluster,不然会无法进行正确的BGP。
目前K8S已经开始支持对LoadBalancer Service指定多协议,因此除了MetalLB提供的IP地址共享的方式,也可以使用原生的功能。