EDT限速: 原理与实现
Kubernetes中,可以通过设置Pod的Annotation kubernetes.io/ingress-bandwidth与kubernetes.io/egress-bandwidth对容器进行带宽限制,bandwidth CNI在容器veth pair的host端设置tc tbf(Token Bucket Filter,令牌桶过滤器)实现限速功能。Cilium通过EDT(Earliest Departure Time)替代令牌桶算法进行限速,在延迟与CPU使用率上都有更好表现。
EDT原理
EDT通过确保数据包不早于某个时间点发送,来控制带宽,而这个时间点是通过上一个数据包的发送时间加上一个延迟来确定的。数据包延迟的计算公式如下所示。
delay_ns = skb->len * NS_PER_SEC / aggregate_state->rate_limit_bps例如,对容器限速10Kbit/s,那容器发送1Kbit大小的包,需要在上一个包发送0.1s之后。似乎可以理解为另一种形式的令牌桶,只不过数据包发送的“成本”由令牌变成了时间片。
引用google分享的Replacing HTB with EDT and BPF 中的描述,EDT限速流程如下图所示:数据包在进入MQ队列之前,被设置skb->tstamp;在FQ队列中,确保数据包不会早于skb->tstamp设置的时间被发出。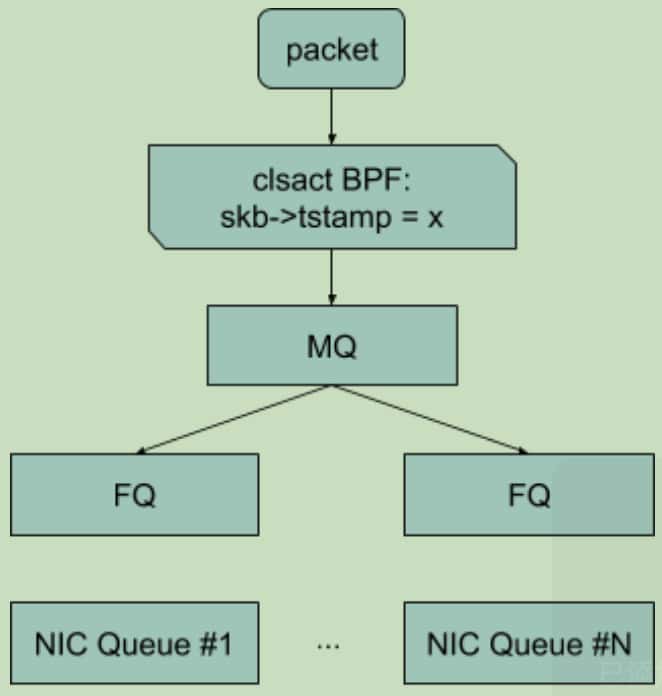
MQ:引用相关Patch里的介绍如下。是个多队列的框架,使用hash函数将流量分配到下面的多个队列。
The
mqqdisc is a dummy qdisc which sets up an array ofpfifo_fastqueues as a Traffic Controltc classunder the rootmq qdisc. Onepfifo_fastqueue is created for each hardware queue.Traffic is placed into each queue using a hash function. This should allow traffic to spread across the multiple queues.
FQ:公平队列,在被修改为EDT mode 后,能确保队列中的数据包不会早于
skb->tstamp设置的时间被发出。引用Evolving from AFAP: Teaching NICs about time 分享里的一个图,其核心结构是一个timestamp的优先循环队列。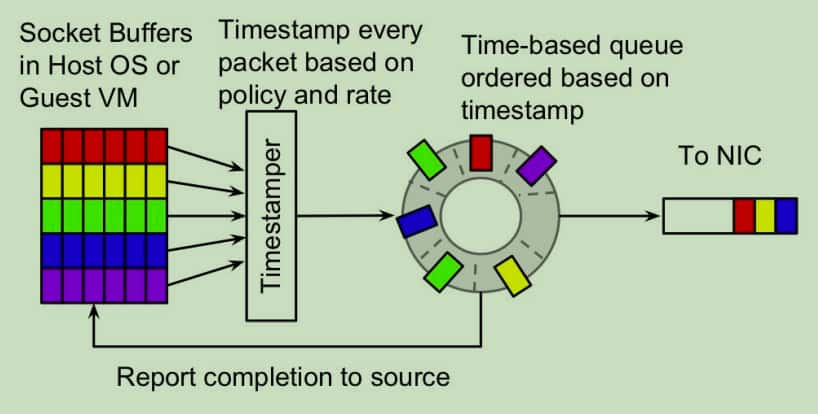
Cilium中的实现
Cilium使用EDT实现了Bandwidth Manager ,具体实现如下:
Cilium Daemon启动时需要判断内核是否能支持EDT
pkg/bandwidth/bandwidth.go
func ProbeBandwidthManager() {
if h := probes.NewProbeManager().GetHelpers("sched_cls") ...
if _, err := sysctl.Read("net.core.default_qdisc") ...
}接着配置系统参数,修改主机网卡队列类型
pkg/bandwidth/bandwidth.go
func InitBandwidthManager() {
// 先设置一些系统参数,包括将默认的队列设置为`fq`,将拥塞算法设置为BBR。
...
congctl := "cubic"
if option.Config.EnableBBR {
congctl = "bbr"
}
...
baseSettings := []setting{
{"net.core.netdev_max_backlog", "1000"},
{"net.core.somaxconn", "4096"},
{"net.core.default_qdisc", "fq"},
{"net.ipv4.tcp_max_syn_backlog", "4096"},
{"net.ipv4.tcp_congestion_control", congctl},
}
...
// 再为cilium使用的宿主机网卡设备添加mq qdisc,子队列会自动创建FQ;如果不支持mq,则直接创建FQ
for _, device := range option.Config.GetDevices() {
...
qdisc = &netlink.GenericQdisc{
QdiscAttrs: netlink.QdiscAttrs{
LinkIndex: link.Attrs().Index,
Parent: netlink.HANDLE_ROOT,
},
QdiscType: "mq",
}
which := "mq with fq leafs"
if err := netlink.QdiscReplace(qdisc); err != nil {
// No MQ support, so just replace to FQ directly.
fq := &netlink.Fq{
QdiscAttrs: netlink.QdiscAttrs{
LinkIndex: link.Attrs().Index,
Parent: netlink.HANDLE_ROOT,
},
Pacing: 1,
}
...
which = "fq"
}
log.WithField("device", device).Infof("Setting qdisc to %s", which)
}
}
数据包经过容器tc bpf程序,设置聚合
bpf/bpf_lxc.c
// 加载在每个容器的veth pair的tc层,设置aggregate。对mq来说,能将容器所有的包都聚合到一个fq子队列,防止数据包的乱序发送
__section("from-container")
int handle_xgress(struct __ctx_buff *ctx)
{
...
edt_set_aggregate(ctx, LXC_ID);
...
}数据包到宿主机网卡准备发出时,经宿主机的bpf程序重新设置发送时间tstamp,接下来就由内核的fq队列进行发送。
bpf/bpf_host.c
__section("to-netdev")
int to_netdev(struct __ctx_buff *ctx __maybe_unused)
{
...
#if defined(ENABLE_BANDWIDTH_MANAGER)
ret = edt_sched_departure(ctx);
/* No send_drop_notify_error() here given we're rate-limiting. */
if (ret == CTX_ACT_DROP) {
update_metrics(ctx_full_len(ctx), METRIC_EGRESS,
-DROP_EDT_HORIZON);
return ret;
}
#endif
...
}
bpf/lib/edt.h
static __always_inline int edt_sched_departure(struct __ctx_buff *ctx)
{
// aggregate记录在ctx->queue_mapping
aggregate.id = edt_get_aggregate(ctx);
if (!aggregate.id)
return CTX_ACT_OK;
info = map_lookup_elem(&THROTTLE_MAP, &aggregate);
now = ktime_get_ns();
t = ctx->tstamp;
if (t < now)
t = now;
// 计算当前数据包的延迟(发送成本)
delay = ((__u64)ctx_wire_len(ctx)) * NSEC_PER_SEC / info->bps;
// info->t_last 记录了上一个数据包的最早发送时间,t_next是当前数据包的最早发送时间
t_next = READ_ONCE(info->t_last) + delay;
if (t_next <= t) {
// 数据包的最早发送时间早于当前,可以直接发送
WRITE_ONCE(info->t_last, t);
return CTX_ACT_OK;
}
// 防止发送时间较远的数据包长时间填充fq,see also 39d010504e6b ("net_sched:* sch_fq: add horizon attribute")
if (t_next - now >= info->t_horizon_drop)
return CTX_ACT_DROP;
WRITE_ONCE(info->t_last, t_next);
// 设置最早发送时间
ctx->tstamp = t_next;
return CTX_ACT_OK;
}实验
代码edt.c:
#include <linux/types.h>
#include <bpf/bpf_helpers.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/pkt_cls.h>
#include <linux/swab.h>
#include <stdint.h>
#include <linux/ip.h>
struct bpf_elf_map
{
__u32 type;
__u32 size_key;
__u32 size_value;
__u32 max_elem;
__u32 flags;
__u32 id;
__u32 pinning;
__u32 inner_id;
__u32 inner_idx;
};
#define NS_PER_SEC 1000000000ULL
#define PIN_GLOBAL_NS 2
#ifndef __section
#define __section(NAME) \
__attribute__((section(NAME), used))
#endif
#ifndef __READ_ONCE
#define __READ_ONCE(X) (*(volatile typeof(X) *)&X)
#endif
#ifndef __WRITE_ONCE
#define __WRITE_ONCE(X, V) (*(volatile typeof(X) *)&X) = (V)
#endif
/* {READ,WRITE}_ONCE() with verifier workaround via bpf_barrier(). */
#ifndef READ_ONCE
#define READ_ONCE(X) \
({ typeof(X) __val = __READ_ONCE(X); \
bpf_barrier(); \
__val; })
#endif
#ifndef WRITE_ONCE
#define WRITE_ONCE(X, V) \
({ typeof(X) __val = (V); \
__WRITE_ONCE(X, __val); \
bpf_barrier(); \
__val; })
#endif
#ifndef barrier
#define barrier() asm volatile("" \
: \
: \
: "memory")
#endif
static __always_inline void bpf_barrier(void)
{
/* Workaround to avoid verifier complaint:
* "dereference of modified ctx ptr R5 off=48+0, ctx+const is allowed,
* ctx+const+const is not"
*/
barrier();
}
struct bpf_elf_map __section("maps") rate_map = {
.type = BPF_MAP_TYPE_HASH,
.size_key = sizeof(__u32),
.size_value = sizeof(__u64),
.pinning = PIN_GLOBAL_NS,
.max_elem = 16,
};
struct bpf_elf_map __section("maps") tstamp_map = {
.type = BPF_MAP_TYPE_HASH,
.size_key = sizeof(__u32),
.size_value = sizeof(__u64),
.max_elem = 16,
};
__section("tc/edt") int edt(struct __sk_buff *skb)
{
void *data_end = (void *)(unsigned long)skb->data_end;
__u64 *rate, *tstamp, delay_ns, now, t, t_next;
void *data = (void *)(unsigned long)skb->data;
struct iphdr *ip = data + sizeof(struct ethhdr);
struct ethhdr *eth = data;
if (data + sizeof(struct ethhdr) > data_end)
return TC_ACT_OK;
if (eth->h_proto != ___constant_swab16(ETH_P_IP) &&
eth->h_proto != ___constant_swab16(ETH_P_IPV6))
return TC_ACT_OK;
if (data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end)
return TC_ACT_OK;
rate = bpf_map_lookup_elem(&rate_map, &ip->daddr);
if (!rate)
{
return TC_ACT_OK;
}
now = bpf_ktime_get_ns();
t = skb->tstamp;
if (t < now)
t = now;
delay_ns = skb->len * NS_PER_SEC / (*rate);
tstamp = bpf_map_lookup_elem(&tstamp_map, &ip->daddr);
if (!tstamp)
{
bpf_map_update_elem(&tstamp_map, &ip->daddr, &t, BPF_ANY);
return TC_ACT_OK;
}
t_next = READ_ONCE(*tstamp) + delay_ns;
if (t_next <= t)
{
WRITE_ONCE(*tstamp, t);
return TC_ACT_OK;
}
WRITE_ONCE(*tstamp, t_next);
skb->tstamp = t_next;
return TC_ACT_OK;
}
char __license[] __section("license") = "GPL";在ubuntu上测试,eno1为主机网卡。执行如下命令:
// 创建qdisc,由于我的网卡不支持多队列,跳过mq,直接创建fq
$ tc qdisc add dev eno1 root handle 1: fq
// 编译bpf,加载到egress
$ clang -O2 -Wall -target bpf -c edt.c -o edt.o
$ tc qdisc add dev eno1 clsact
$ tc filter add dev eno1 egress bpf direct-action obj edt.o sec tc/edt
$ bpftool net show
// 更新rate_map,限制目的地为192.168.2.1(c0a80201)的流量最大为10Mbits/s(value需要转换为byte,即1250000)
$ bpftool map update pinned /sys/fs/bpf/tc/globals/rate_map key 0xC0 0xA8 0x02 0x01 value 0xd0 0x12 0x13 0 0 0 0 0
// iperf测试
$ iperf3 -c 192.168.2.1
Connecting to host 192.168.2.1, port 5201
[ 5] local 192.168.2.2 port 28180 connected to 192.168.2.1 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1.38 MBytes 11.6 Mbits/sec 0 33.9 KBytes
[ 5] 1.00-2.00 sec 1.12 MBytes 9.38 Mbits/sec 0 33.9 KBytes
[ 5] 2.00-3.00 sec 1.24 MBytes 10.4 Mbits/sec 0 33.9 KBytes
[ 5] 3.00-4.00 sec 1.12 MBytes 9.38 Mbits/sec 0 33.9 KBytes
// 限制20Mbits/s
$ bpftool map update pinned /sys/fs/bpf/tc/globals/rate_map key 0xC0 0xA8 0x02 0x01 value 0xA0 0x25 0x26 0 0 0 0 0
$ iperf3 -c 192.168.2.1
Connecting to host 192.168.2.1, port 5201
[ 5] local 192.168.2.2 port 28184 connected to 192.168.2.1 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 2.50 MBytes 21.0 Mbits/sec 0 33.9 KBytes
[ 5] 1.00-2.00 sec 2.36 MBytes 19.8 Mbits/sec 0 33.9 KBytes
[ 5] 2.00-3.00 sec 2.49 MBytes 20.9 Mbits/sec 0 42.4 KBytes参考
https://blog.csdn.net/ByteDanceTech/article/details/120878281
https://www.51cto.com/article/685201.html