Kubernetes Pod支持RDMA网卡的几种方式
最近调研了几种实现Kubernetes Pod支持RDMA网卡的库,粗略的记录下。
FreeFlow
FreeFlow是微软提出的一种RDMA技术,主要用于将RDMA应用在容器中。FreeFlow整体方案由三部分组成:
- FreeFlow network library(FFL),主要实现了Verbs,提供给应用程序调用。
- FreeFlow software路由器(FFR),为主机上的多个容器进行RDMA流量路由。
- FreeFlow network orchestrator(FFO),根据策略(Policies)、网络状态(Stats)控制FFR的行为。
FreeFlow架构如下,灰色部分为FreeFlow组件。
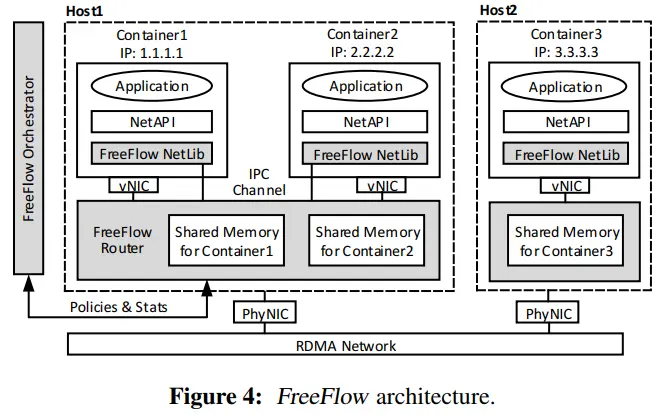
FreeFlow的原理:一般应用程序利用RDMA API直接向硬件NIC发送命令,以实现控制和数据路径功能。FreeFlow拦截应用程序和物理网卡之间的通信,并通过软件的FreeFlow Router进行容器之间的路由,通过FreeFlow Netlib实现应用程序向硬件NIC的控制,从而实现控制平面和数据平面策略。FreeFlow实现了Verbs,因此对应用程序与硬件NIC来说,都是透明的。
FreeFlow的缺点:
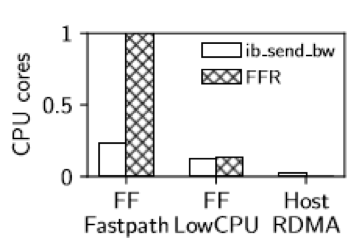
- FreeFlow提供了两种模式:Fastpath和LowCPU。Fastpath能提供接近于Host RDMA的传输性能,但为了实现零拷贝,需要绑核进行轮询,耗费大量CPU资源。而LowCPU模式,传输性能明显下降。

rit-k8s-rdma
rit-k8s-rdma通过CNI的方式给Kubernetes分配RDMA网卡,其主要由三部分构成: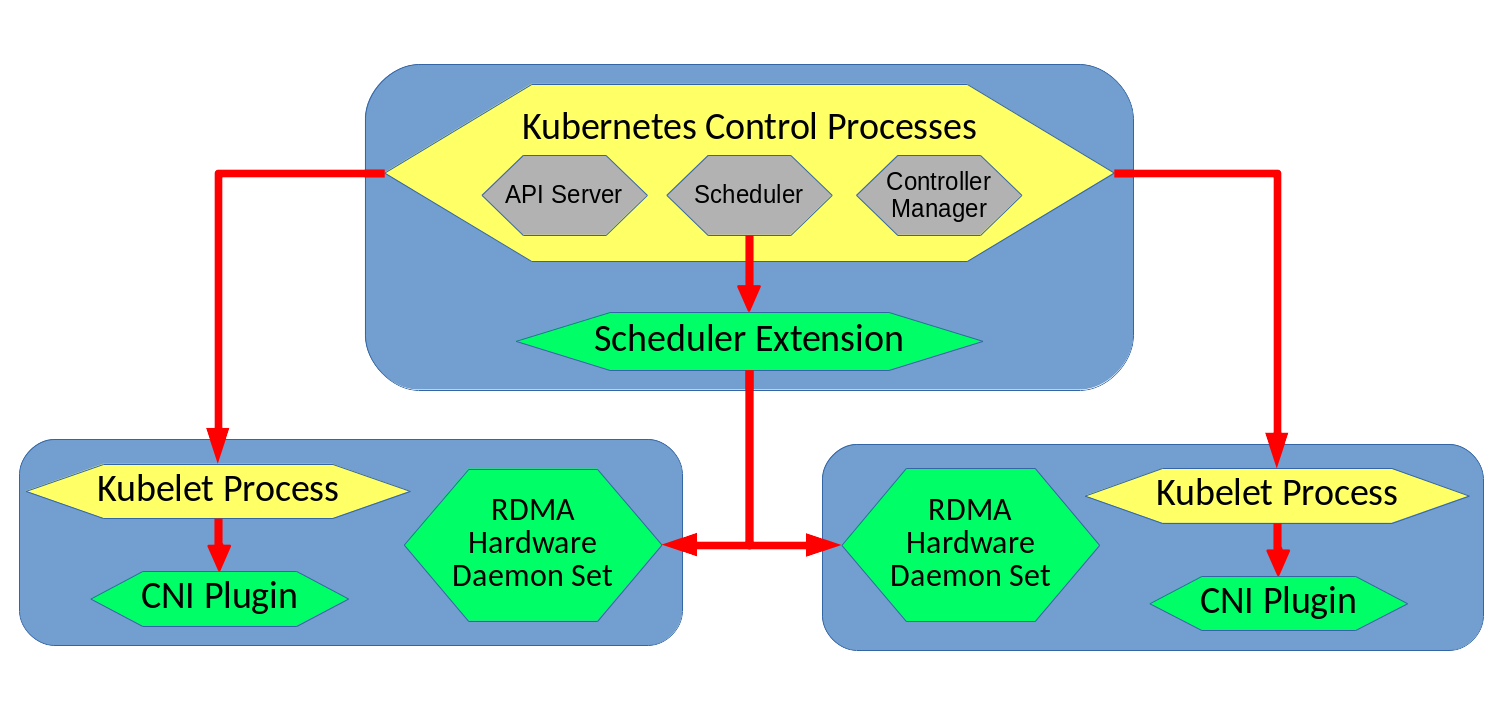
- Scheduler Extension: 基于Kubernetes Scheduler的扩展架构开发,用于将Pod调度到具有足够RDMA资源的节点上。
- RDMA Hardware Daemon Set:部署在每个节点上,一是用于初始化节点上的RDMA SR-IOV设备,二是用于提供RESTful接口,提供关于PF、VF的元数据。
- CNI Plugin:用于给Pod分配RDMA网卡的CNI插件。基于Mellanox CNI开发,Mellanox CNI可以为每个Pod分配一个RDMA VF接口,而rit-k8s-rdma cni plugin能为Pod分配多个RDMA VF接口,并且为每个RDMA VF接口配置带宽预留或限制。
- Dummy Device Plugin:部署在每个节点上。由于使用RDMA的Pod一般需要访问
/dev/infiniband目录,为了不使用特权Pod,通过Kubernetes Device Plugin机制将此Device通过Dummy Device Plugin返回给Kubelet,作为Pod的特权目录。
rit-k8s-rdma的优点:rit-k8s-rdma本质上是在Mellanox-network-operator的SR-IOV模式下添加了更加合理的调度、一个Pod分配多个RDMA VF接口、带宽限制等功能,通过在整体集群视角下的调度,以及节点层面的带宽限制,能更加合理的利用RDMA资源。
rit-k8s-rdma的缺点:
- 调度的算法过于简单。仅考虑到RDMA资源数量上是否满足Pod的需要,未考虑的RDMA资源的拓扑信息,进行优选调度。例如根据RDMA设备与GPU在节点上的拓扑,为Pod选取满足GPU与RDMA在同一PCIe设备上的节点;或是针对大模型训练任务中,考虑整体集群的流量拓扑,避免某些节点之间通信过于繁忙,导致拥塞。
Mellanox-network-operator
Mellanox-network-operator也被叫NVIDA Network Operator,是NVIDA开源的一套RDMA与Kubernetes集成方案,利用Kubernetes CRDs与Operator SDK来管理RDMA网络,为Pod支持RDMA网卡与GPUDirect特性。Mellanox-network-operator更像是一组RDMA集成方案的集合,例如通过Macvlan的方式添加RDMA网卡,或是SR-IOV的方式添加RDMA网卡,亦或是使用Share RDMA的方式,将RDMA网卡设备添加到多个Pod中共同使用。用户通过设置helm value或是修改CRD,来使用某一种RDMA集成方案。
Mellanox-network-operator主要组件包括:
- Mellanox drivers:Mellanox网卡驱动。
- nvidia-peermem:基于Mellanox IB的HCAs,提供对NVIDIA GPU显存的点对点读写。
- k8s device plugin:用于管理RDMA网卡的Kubernetes Device Plugin。
- SR-IOV Operator:用于部署SR-IOV容器网络。
- Kubernetes CNI:包括用于容器分配多网络的Mutlus CNI、分配RDMA网络的Mellanox CNI.
CRD
Mellanox-network-operator定义了四个CRD,用于配置部署。
NICClusterPolicy CRD
用于配置全局的部署参数,operator只会使用名为“nic-cluster-policy”的实例,忽略其他的实例。参数包括:
- 配置容器化的mellanox OFED Driver的
ofedDriver。 - 配置rdma share模式下device plugin的
rdmaSharedDevicePlugin。 - 配置sr-iov模式下sr-iov device plugin的
sriovDevicePlugin。 - 配置GPUDirect特性下nvidia peermem的
nvPeerDriver - 用于配置InfiniBand Kubernetes的
ibKubernetes,InfiniBand Kubernetes能配合IOV CNI与Intel Multus CNI工作,目前只用于NVIDIA UFM(Unified Fabric Manager)的Guid生成,配置到Pod的annotation上。 - 用于配置第二张Pod网卡的
SecondaryNetwork,第二网络可以是
官方的样例:
apiVersion: mellanox.com/v1alpha1
kind: NicClusterPolicy
metadata:
name: nic-cluster-policy
namespace: nvidia-network-operator
spec:
ofedDriver:
image: mofed
repository: nvcr.io/nvidia/mellanox
version: 5.9-0.5.6.0
startupProbe:
initialDelaySeconds: 10
periodSeconds: 10
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 30
readinessProbe:
initialDelaySeconds: 10
periodSeconds: 30
rdmaSharedDevicePlugin:
image: k8s-rdma-shared-dev-plugin
repository: nvcr.io/nvidia/cloud-native
version: v1.3.2
# The config below directly propagates to k8s-rdma-shared-device-plugin configuration.
# Replace 'devices' with your (RDMA capable) netdevice name.
config: |
{
"configList": [
{
"resourceName": "rdma_shared_device_a",
"rdmaHcaMax": 1000,
"selectors": {
"vendors": ["15b3"],
"deviceIDs": ["1017"],
"ifNames": ["ens2f0"]
}
}
]
}
secondaryNetwork:
cniPlugins:
image: plugins
repository: ghcr.io/k8snetworkplumbingwg
version: v0.8.7-amd64
multus:
image: multus-cni
repository: ghcr.io/k8snetworkplumbingwg
version: v3.8
# if config is missing or empty then multus config will be automatically generated from the CNI configuration file of the master plugin (the first file in lexicographical order in cni-conf-dir)
config: ''
ipamPlugin:
image: whereabouts
repository: ghcr.io/k8snetworkplumbingwg
version: v0.5.4-amd64MacvlanNetwork CRD
用于定义Macvlan类型的第二网络,此CRD会被转成Intel Mutlus CNI的CRD NetworkAttachmentDefinition。
官方样例:
apiVersion: mellanox.com/v1alpha1
kind: MacvlanNetwork
metadata:
name: example-macvlannetwork
spec:
networkNamespace: "default"
master: "ens2f0"
mode: "bridge"
mtu: 1500
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "192.168.2.225/28",
"exclude": [
"192.168.2.229/30",
"192.168.2.236/32"
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info",
"gateway": "192.168.2.1"
}HostDeviceNetwork CRD
用于定义HostDevice类型的第二网络,此CRD会被转成Intel Mutlus CNI的CRD NetworkAttachmentDefinition。
官方样例:
apiVersion: mellanox.com/v1alpha1
kind: HostDeviceNetwork
metadata:
name: example-hostdevice-network
spec:
networkNamespace: "default"
resourceName: "hostdev"
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "192.168.3.225/28",
"exclude": [
"192.168.3.229/30",
"192.168.3.236/32"
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info"
}IPoIBNetwork CRD
用于定义IPoIB类型的第二网络,此CRD会被转成Intel Mutlus CNI的CRD NetworkAttachmentDefinition。
官方样例:
apiVersion: mellanox.com/v1alpha1
kind: IPoIBNetwork
metadata:
name: example-ipoibnetwork
spec:
networkNamespace: "default"
master: "ibs3f1"
ipam: |
{
"type": "whereabouts",
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"range": "192.168.5.225/28",
"exclude": [
"192.168.6.229/30",
"192.168.6.236/32"
],
"log_file" : "/var/log/whereabouts.log",
"log_level" : "info",
"gateway": "192.168.6.1"
}部署方式
Mellanox-network-operator提供了许多种Kubernetes集成RDMA的方式。比如RDMA Shared Device Plugin、Host Device Network、SR-IOV方式等,SR-IOV方式有能分为传统的SR-IOV方式、用于IB网络的SR-IOV方式、用于Nvidia UFM的SR-IOV方式。下面以RoCE场景下(因工作中主要是用RoCE V2,其他方式以后再研究)几种部署方式进行介绍。
RDMA Shared Device Plugin
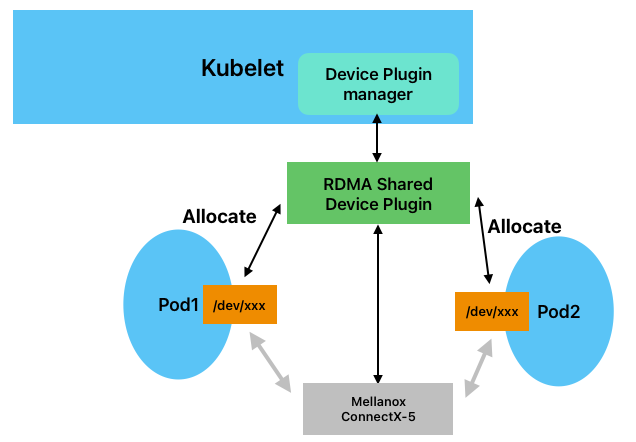
RDMA Shared Device Plugin模式下,RDMA设备通过Device Plugin将device目录传递给容器,多个容器共享RDMA设备。部署后的架构如下图所示:
部署方式:
通过helm部署,helm的values.yaml如下:
nfd:
enabled: true
sriovNetworkOperator:
enabled: false
# NicClusterPolicy CR values:
deployCR: true
ofedDriver:
deploy: true
nvPeerDriver:
deploy: false
rdmaSharedDevicePlugin:
deploy: true
resources:
- name: rdma_shared_device_a
ifNames: [ens1f0]
sriovDevicePlugin:
deploy: falseSecondary Network
Secondary Network模式下,RDMA网卡作为Pod的第二张网卡存在,第二张网卡的实现方式有多种,可以通过上面介绍的CRD进行配置。以macvlan为例,kubelet创建pod时,通过Multus CNI创建两张网卡,其中第一张为主网卡,第二张为使用RDMA设备创建的macvlan网卡,部署后的架构如下图所示: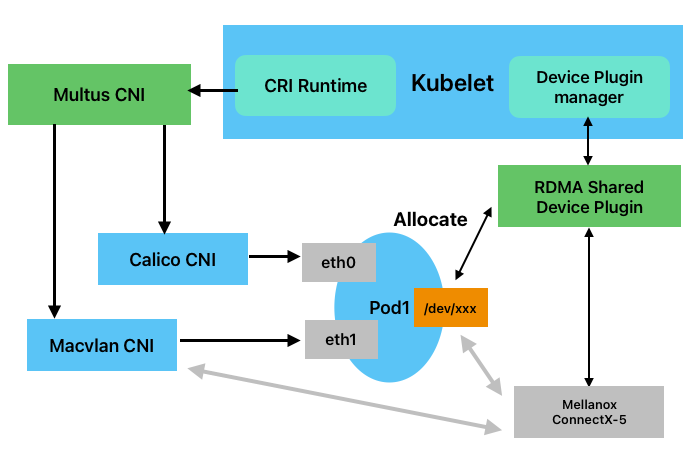
部署方式:
通过helm部署,helm的values.yaml如下:
nfd:
enabled: true
sriovNetworkOperator:
enabled: false
# NicClusterPolicy CR values:
deployCR: true
ofedDriver:
deploy: false
rdmaSharedDevicePlugin:
deploy: true
resources:
- name: rdma_shared_device_a
ifNames: [ens1f0]
secondaryNetwork:
deploy: true
multus:
deploy: true
cniPlugins:
deploy: true
ipamPlugin:
deploy: trueHost Device Network
Host Device Network模式下,RDMA设备会先通过SR-IOV进行虚化,Pod的第二张网卡通过host- dev cni将VF或PF添加到Pod里,部署后的架构如下图所示: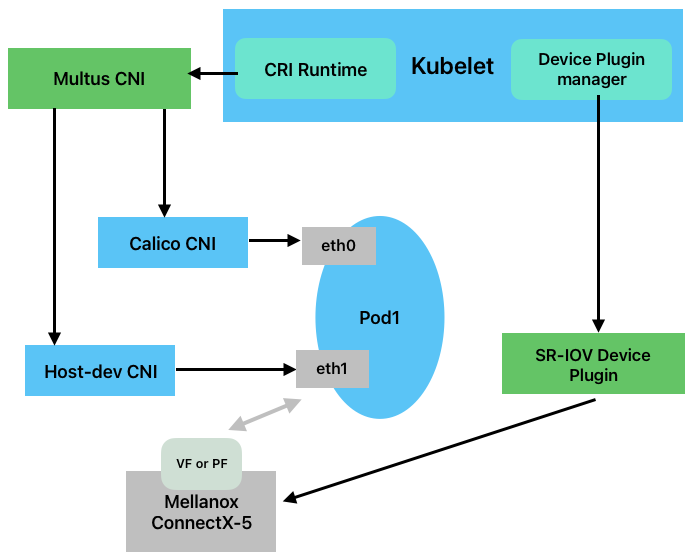
部署方式:
通过helm部署,helm的values.yaml如下:
nfd:
enabled: true
sriovNetworkOperator:
enabled: false
# NicClusterPolicy CR values:
deployCR: true
ofedDriver:
deploy: false
rdmaSharedDevicePlugin:
deploy: false
sriovDevicePlugin:
deploy: true
resources:
- name: hostdev
vendors: [15b3]
secondaryNetwork:
deploy: true
multus:
deploy: true
cniPlugins:
deploy: true
ipamPlugin:
deploy: true除此外还需通过HostDeviceNetwork CRD进行配置。
SR-IOV Operator
SR-IOV Operator模式实际上是通过sriov-network-operator自动配置SR-IOV,然后通过SR-IOV cni配置pod网络,部署后的架构如下图所示:
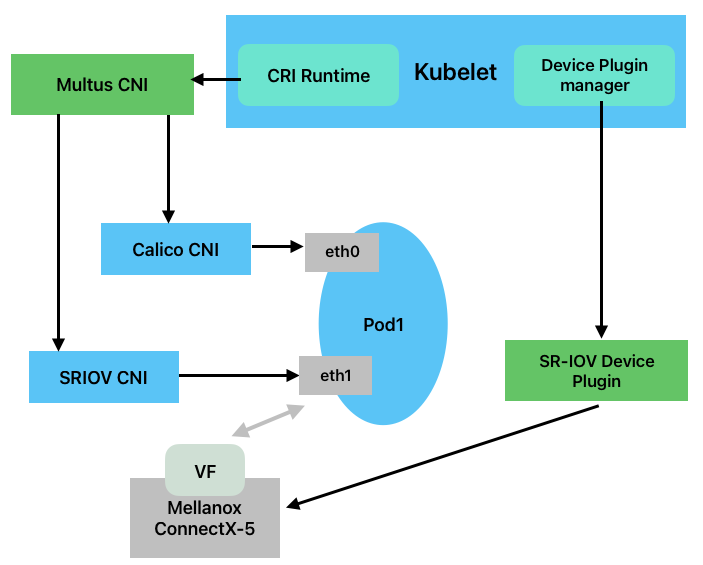
部署方式:
通过helm部署,helm的values.yaml如下:
nfd:
enabled: true
sriovNetworkOperator:
enabled: true
# NicClusterPolicy CR values:
deployCR: true
ofedDriver:
deploy: true
rdmaSharedDevicePlugin:
deploy: false
sriovDevicePlugin:
deploy: false
secondaryNetwork:
deploy: true
multus:
deploy: true
cniPlugins:
deploy: true
ipamPlugin:
deploy: true几种部署方式的比较
各种方式中,SR-IOV Operator在RoCE场景下更具有优势。相比Host Device Network方式,SR-IOV Operator自动化程度更高,通过sriov-network-operator的CRD可以配置各个节点的SR-IOV网卡配置;相比Macvlan的Secondary Network,SR-IOV虚拟化能带来比Macvlan更好的性能。
优缺点
Mellanox-network-operator提供的部署方式与功能特性(例如GPUDirect)是它的优点。缺点在于缺少集群调度层面的控制,与rit-k8s-rdma类似,无法根据设备拓扑进行RDMA资源的最优分配。
总结
上述三种方式中,在RoCE场景下,以Mellanox-Network-Operator的SR-IOV Operator部署方式为最优,但无法实现GPU与RDMA的PCIe对齐,以提高大模型的训练速度。
针对GPU与RDMA的PCIe对齐,Mellanox-Network-Operator的SR-IOV Operator部署方式欠缺的能力主要包括:
1)通过调度,选择可以为Pod分配相同PCIe Switch下GPU与RDMA资源的节点。
2)在节点层面,为Pod分配相同PCIe Switch下GPU与RDMA资源。由于目前NVIDIA GPU、Mellanox RDMA的资源分配方式均是使用Device Plugin机制,Device Plugin的资源分配基本完全由Kubelet决定,而Device Plugin资源的拓扑感知是受Kubelet topology manager控制,Kubelet topology manager只能做到NUMA对齐,因此无法做到PCIe的对齐。