使用Loki监控Kubernetes中的AI训练任务
Loki是一个由Grafana Labs开发的开源日志聚合系统,旨在为云原生架构提供高效的日志处理解决方案。本文将介绍Loki的工作原理、部署方法以及如何在AI训练场景下利用它来监控训练日志。
Loki
Loki使用类似Prometheus的标签索引机制来存储和查询日志数据,它能够快速地进行分布式查询和聚合,而不需要将所有数据都从存储中加载到内存中。相比之下,ELK需要维护一个大的索引,需要更多的存储空间。
一个典型的基于Loki的日志管理系统由3部分组成:
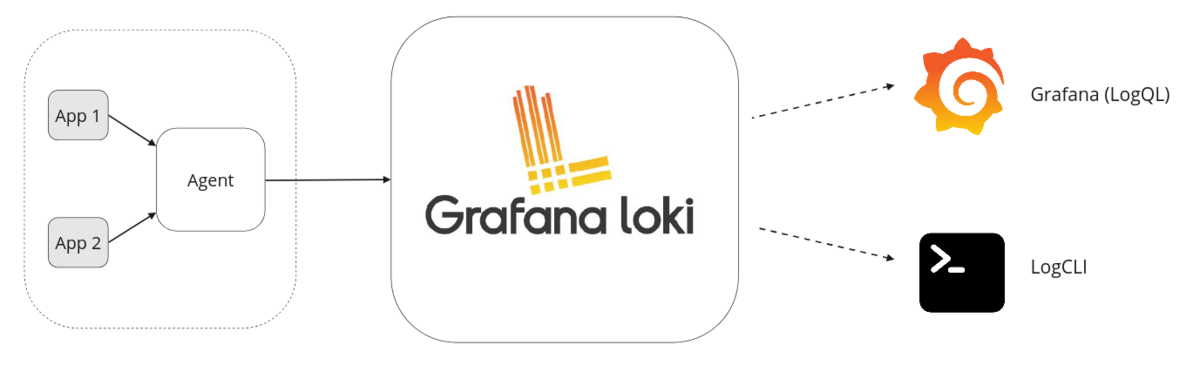
- Agent:用来采集容器日志,一般是Promtail。
- Loki:负责存储日志数据,提供HTTP API的日志查询、数据过滤及筛选能力。
- Grafana:负责展示日志以及从日志中获取的指标。
Loki内部组件包括:

- 分发器(Distributor):负责处理客户端传入的日志流,是写入路径的第一站。分发器会验证日志流的正确性,并确保其符合租户(或全局)限制。验证后的数据块会被分批发送到多个接收器(Ingester)。
- 接收器(Ingester):负责将日志数据写入长期存储后端(如DynamoDB,S3等),并在读取路径返回日志数据。接收器包含一个生命周期管理器,管理其在哈希环中的状态。
- 查询前端(Query Frontend):可选服务,提供查询器API端点,用于加速读取路径。查询前端内部进行一些查询调整,并在内部队列中保留查询。
- 查询器(Querier):处理使用LogQL查询语言的查询,从接收器和长期存储中获取日志。
- Ruler:用于处理告警规则,根据日志产生告警。
部署Loki
通过Helm部署的Loki分两种模式:monolithic、scalable。
scalable模式如下图所示:将各个组件分成多个pod部署,以便于扩展。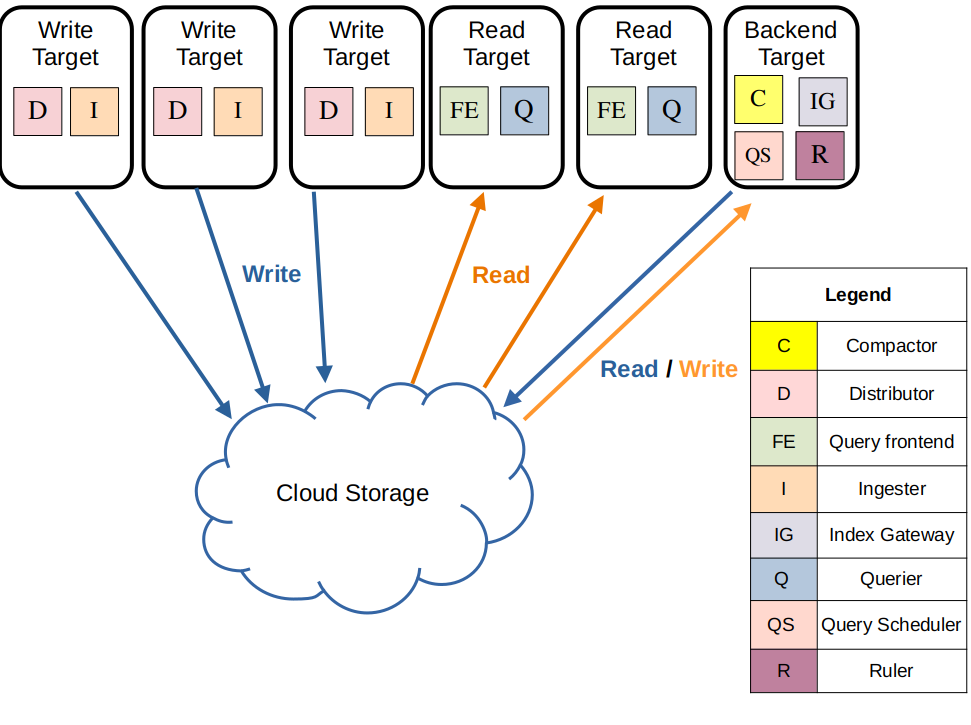
monolithic模式就是all in one,将所有组件使用一个pod部署。当使用monolithic模式的单实例部署时,可以使用本地的filesystem作为后端存储,否则,需要使用对象存储作为后端存储。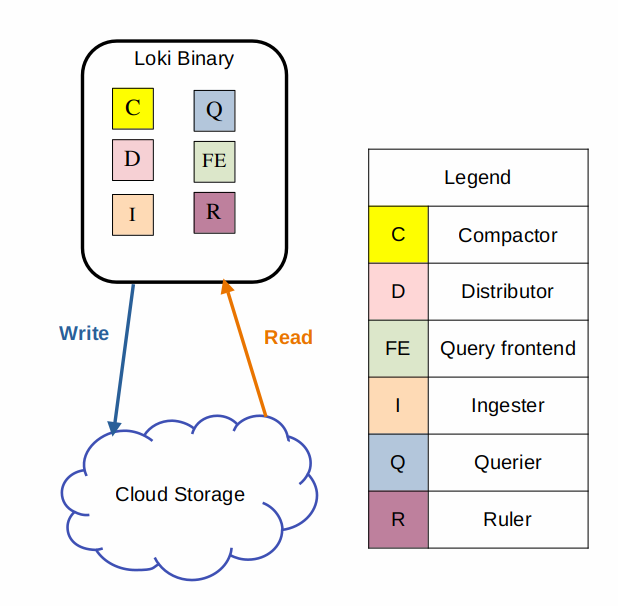
本文使用monolithic模式的单实例进行演示。在部署loki之前,环境里已经通过kube-prometheus部署了Grafana、Alertmanager、Prometheus等。
$ kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 3h35m
blackbox-exporter-6b5475894-pjjvk 3/3 Running 0 3h42m
grafana-64c4f67f5b-qv47b 1/1 Running 0 3h42m
kube-state-metrics-65474fb4c6-d7wcn 3/3 Running 0 3h41m
node-exporter-sm4tp 2/2 Running 0 3h41m
prometheus-adapter-74894c5547-c99wn 1/1 Running 0 3h41m
prometheus-adapter-74894c5547-hggjt 1/1 Running 0 3h41m
prometheus-k8s-0 2/2 Running 0 3h39m
prometheus-operator-5575b484df-mrtnm 2/2 Running 0 3h41m通过helm部署monolithic loki。
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update创建loki-value.yaml
loki:
commonConfig:
replication_factor: 1
storage:
type: 'filesystem'
// 关闭鉴权,方便配置Grafana
auth_enabled: false
singleBinary:
replicas: 1
monitoring:
// 默认会部署Grafana Agent,这里关闭,后面单独部署promtail
selfMonitoring:
enabled: false
grafanaAgent:
installOperator: false
// 默认会部署Canary,用于对loki探活,这里关闭
lokiCanary:
enabled: false
// 关闭helm按照前的test
test:
enabled: false
// 关闭gateway,因为没用到ingress
gateway:
enabled: false安装loki
$ helm install --values loki-value.yaml loki grafana/loki创建promtail-value.yaml
config:
# publish data to loki
clients:
- url: http://loki.default.svc.cluster.local:3100/loki/api/v1/push
tenant_id: 1安装promtail
$ helm install --values promtail-values.yaml promtail grafana/promtail查看Pod
$ kubectl get po
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 23h
promtail-glm2t 1/1 Running 0 22h配置Loki到Grafana中。新添Data sources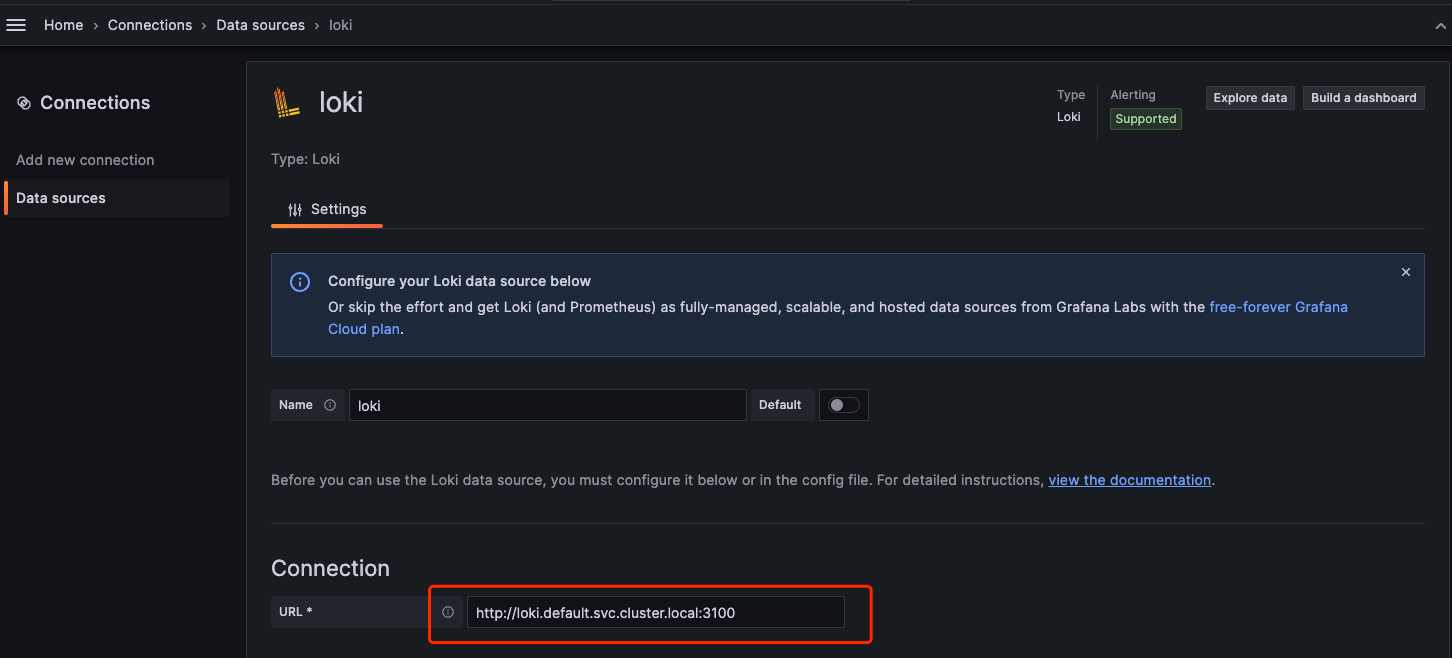
训练样例
接下来,我们部署training-operator,通过MNIST训练产生一些训练日志。
$ kubectl apply -k "github.com/kubeflow/training-operator/manifests/overlays/standalone?ref=v1.7.0"
$ kubectl get po -n kubeflow
NAME READY STATUS RESTARTS AGE
training-operator-64c768746c-gsqkf 1/1 Running 0 1s
$ kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/pytorch/simple.yaml
$ kubectl get po -n kubeflow
NAME READY STATUS RESTARTS AGE
pytorch-simple-master-0 0/1 Completed 0 22m
pytorch-simple-worker-0 0/1 Completed 0 22m
training-operator-64c768746c-gsqkf 1/1 Running 0 24m
$ kubectl logs --tail 10 pytorch-simple-master-0 -n kubeflow
2024-03-19T08:51:02Z INFO Train Epoch: 1 [55040/60000 (92%)] loss=0.6565
2024-03-19T08:51:07Z INFO Train Epoch: 1 [55680/60000 (93%)] loss=0.5459
2024-03-19T08:51:11Z INFO Train Epoch: 1 [56320/60000 (94%)] loss=0.5875
2024-03-19T08:51:16Z INFO Train Epoch: 1 [56960/60000 (95%)] loss=0.5498
2024-03-19T08:51:20Z INFO Train Epoch: 1 [57600/60000 (96%)] loss=0.7155
2024-03-19T08:51:25Z INFO Train Epoch: 1 [58240/60000 (97%)] loss=0.7295
2024-03-19T08:51:29Z INFO Train Epoch: 1 [58880/60000 (98%)] loss=0.8877
2024-03-19T08:51:34Z INFO Train Epoch: 1 [59520/60000 (99%)] loss=0.5380
2024-03-19T08:51:44Z INFO {metricName: accuracy, metricValue: 0.7312};{metricName: loss, metricValue: 0.6644}获取loss信息
在grafana中新建一个panel,执行如下LogQL进行查询。通过关键字Train过滤出训练的日志,通过pattern匹配其中的loss与step。
{app="pytorch-simple",pod="pytorch-simple-master-0"} |= "Train" | pattern "<time> <_> Train Epoch: 1 [<step>/<_> <_>] loss=<loss>" 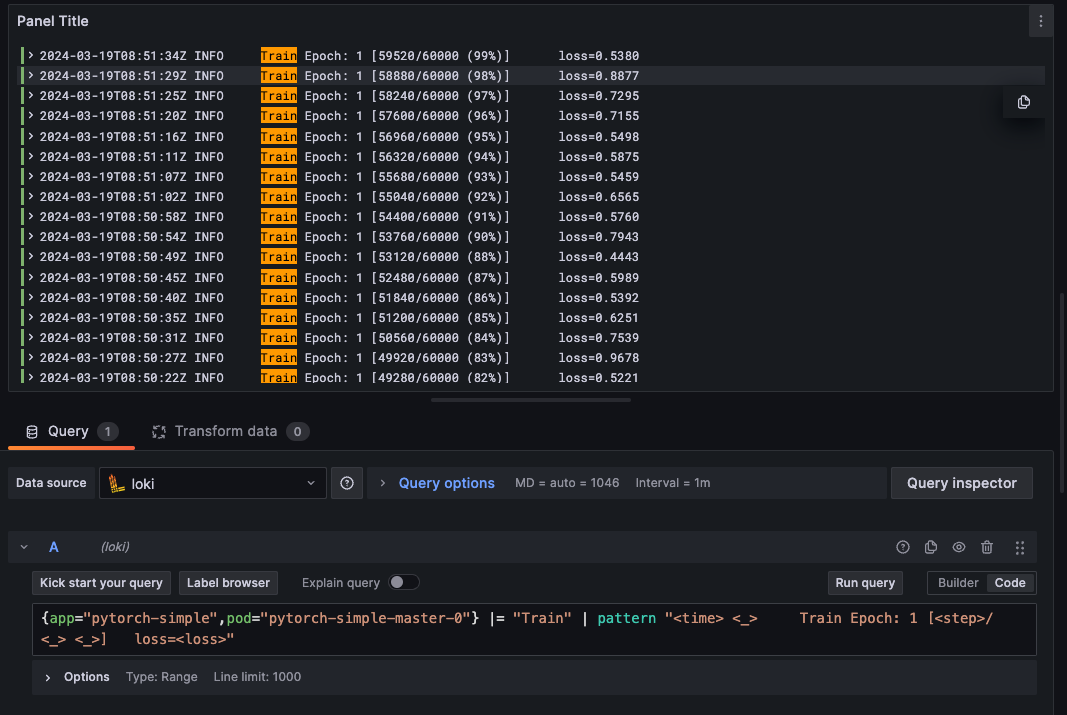
接下来通过Extract fields、Convert field type、Sort by三个Transform来提取label并整形。可以使用Table样式查看。![]()
使用XY Chart进行绘制。
修改下X、Y的data,使用Lines的方式进行显示。最终我们就获取到一个训练任务中step-loss的可视图。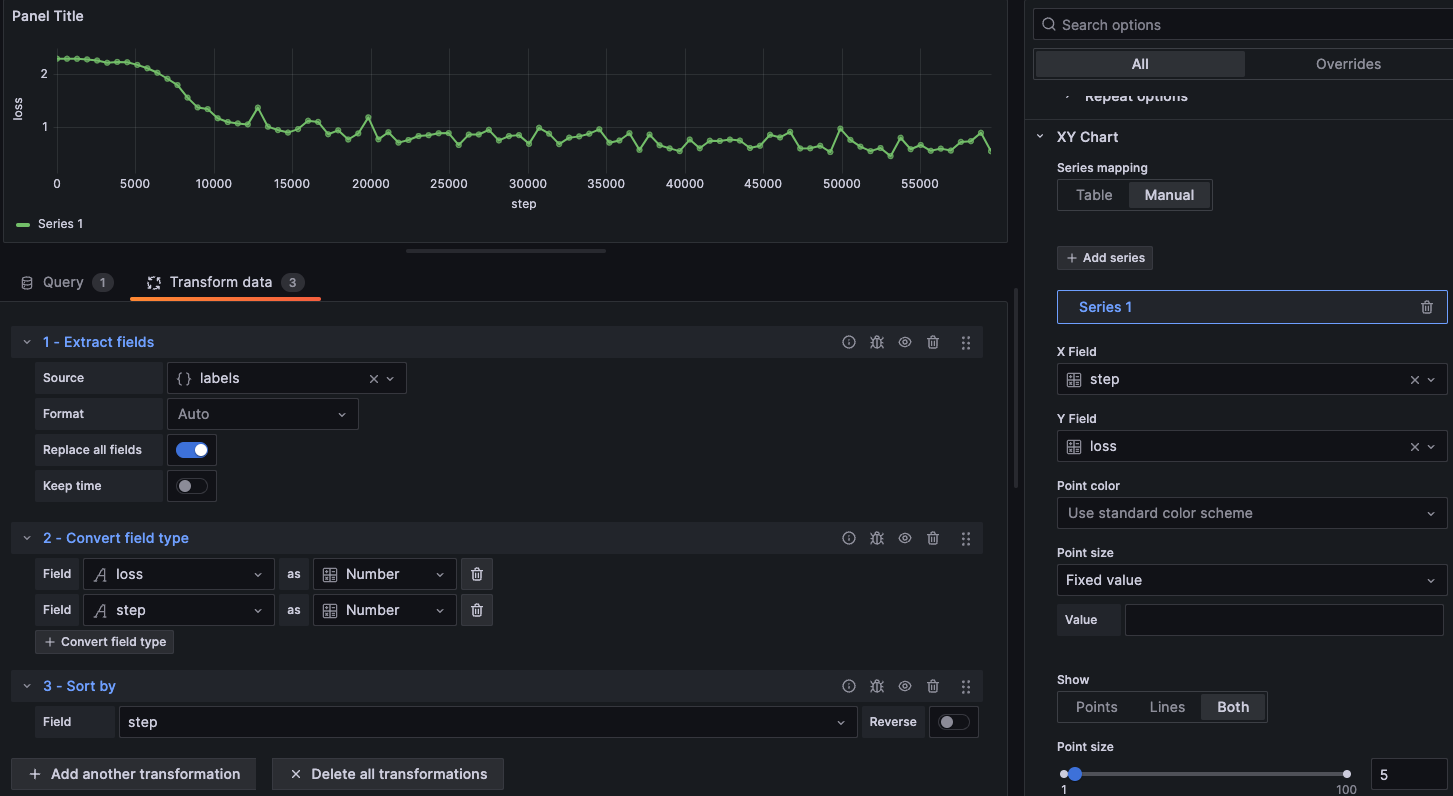
监控、分析报错
通过Loki的Ruler组件,可以实现基于日志的告警功能。可以实现对训练任务所在namespace下,所有pod的日志监控。
首先修改Loki配置,配置ruler
$ kubectl edit cm lokiruler部分修改如下
...
ruler:
storage:
type: local
local:
directory: /etc/loki/rules
alertmanager_url: http://alertmanager-main.monitoring.svc.cluster.local:9093
ring:
kvstore:
store: inmemory
enable_alertmanager_v2: true
...创建一个告警规则,当日志中出现error、fail、failed、invalid等字符时,触发告警。
$ kubectl create cm loki-rules --from-file=log-alert.yml
configmap/loki-ruler created
$ kubectl get cm loki-rules
NAME DATA AGE
loki-rules 1 11s
$ kubectl get cm loki-rules -o yaml
apiVersion: v1
data:
log-alert.yml: |
groups:
- name: training-log-alert
rules:
- alert: errorLog
expr: count_over_time({namespace="kubeflow"} |~ "^.*(?i)(error|fail|failed|invalid).*$" [1m]) > 0
for: 0m
labels:
severity: critical
instance: "{{ $labels.job }}"
annotations:
summary: "get error log in pod"
description: "get error {{ $value }} log in pod {{ $labels.pod }} in namespace {{ $labels.namespace }} in the last minute"
kind: ConfigMap
metadata:
creationTimestamp: "2024-03-21T01:24:15Z"
name: loki-ruler
namespace: default
resourceVersion: "6445339"
uid: 55f7be3a-1e41-4b47-bb9e-637191bc967e接着重新创建pytorch-simple,并在训练过程中,删除worker,以产生故障日志。
$ kubectl delete -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/pytorch/simple.yaml
$ kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/pytorch/simple.yaml
$ kubectl delete po pytorch-simple-worker-0 -n kubeflow查看master日志,可以看到保存日志已产生
$ kubectl logs --tail 10 pytorch-simple-master-0 -n kubeflow
2024-03-21T01:39:55Z INFO Train Epoch: 1 [12160/60000 (20%)] loss=1.0480
2024-03-21T01:39:59Z INFO Train Epoch: 1 [12800/60000 (21%)] loss=1.3666
Traceback (most recent call last):
File "/opt/pytorch-mnist/mnist.py", line 171, in <module>
main()
File "/opt/pytorch-mnist/mnist.py", line 163, in main
train(args, model, device, train_loader, optimizer, epoch)
File "/opt/pytorch-mnist/mnist.py", line 43, in train
loss.backward()
File "/opt/conda/lib/python3.6/site-packages/torch/tensor.py", line 102, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/opt/conda/lib/python3.6/site-packages/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/opt/conda/lib/python3.6/site-packages/torch/nn/parallel/distributed_cpu.py", line 92, in allreduce_params
dist.all_reduce(coalesced)
File "/opt/conda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 838, in all_reduce
work.wait()
RuntimeError: [/opt/conda/conda-bld/pytorch_1544199946412/work/third_party/gloo/gloo/transport/tcp/pair.cc:543] Connection closed by peer [10.0.0.252]:16575进入alertManager,可以看到相应告警。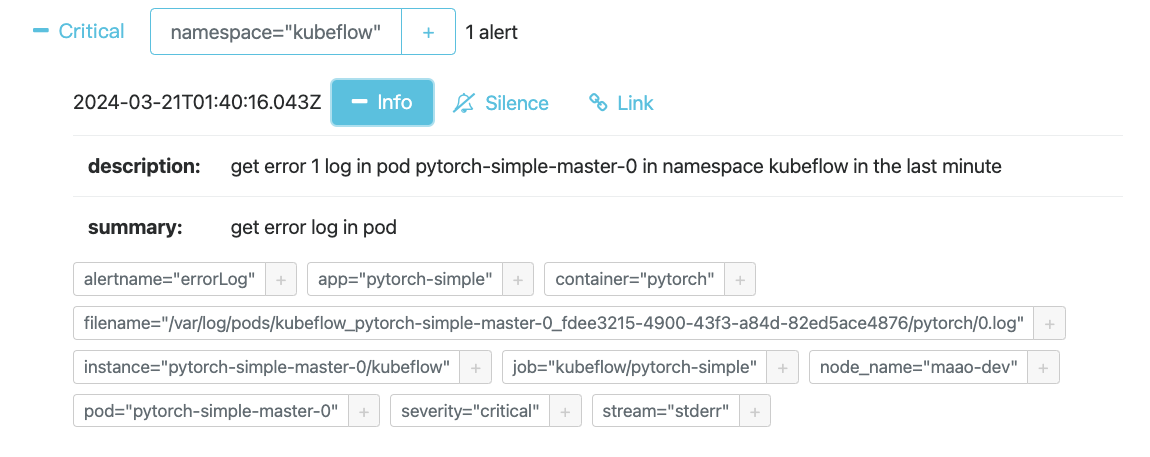
可以修改loki-rulesConfigMap,添加更多的告警规则。比如根据日志的warning数量来产生告警。
$ kubectl get cm loki-rules -o yaml
apiVersion: v1
data:
log-alert.yml: |
groups:
- name: training-log-alert
rules:
- alert: errorLog
expr: count_over_time({namespace="kubeflow"} |~ "^.*(?i)(error|fail|failed|invalid).*$" [1m]) > 0
for: 0m
labels:
severity: critical
instance: "{{ $labels.job }}"
annotations:
summary: "get error log in pod"
description: "get error {{ $value }} log in pod {{ $labels.pod }} in namespace {{ $labels.namespace }} in the last minute"
- alert: tooMuchWarningLog
expr: sum(rate({namespace="kubeflow"} |~ "^.*(?i)(warning).*$" [5m])) by (job) / sum(rate({namespace="kubeflow"} [5m])) by (job) > 0.05
for: 0m
labels:
severity: warning
instance: "{{ $labels.job }}"
annotations:
summary: "get too many warning in pod"
description: "pod {{ $labels.pod }} in namespace {{ $labels.namespace }} has encountered {{ printf \"%.2f\" $value }} warning log in the last 5 minute"
kind: ConfigMap
metadata:
creationTimestamp: "2024-03-21T01:27:48Z"
name: loki-rules
namespace: default
resourceVersion: "6480454"
uid: b70535fa-e44f-4727-ab7e-4f17fe75ba34修改configmap后,在kubelet重新remount之后,loki会自动更新告警规则。从loki的日志中可见相应的更新日志。
在grafana中可以看到告警规则已更新。