实践:使用SR-IOV在k8s集群中提供rdma网卡
生产环境中,遇到节点上8张GPU、2张RDMA网卡的情况,RDMA网卡使用RoCE V2,需要对RDMA网卡做SR-IOV,以做到GPU与RDMA网卡数量1:1。记录下操作过程与其中遇到的坑。
环境背景
每个节点上有两张Mellanox ConnectX6,并且采用多轨连线。集群部分节点的参数网络拓扑如下图所示(图中不包含存储网、业务网、管理网、spine交换机等)。
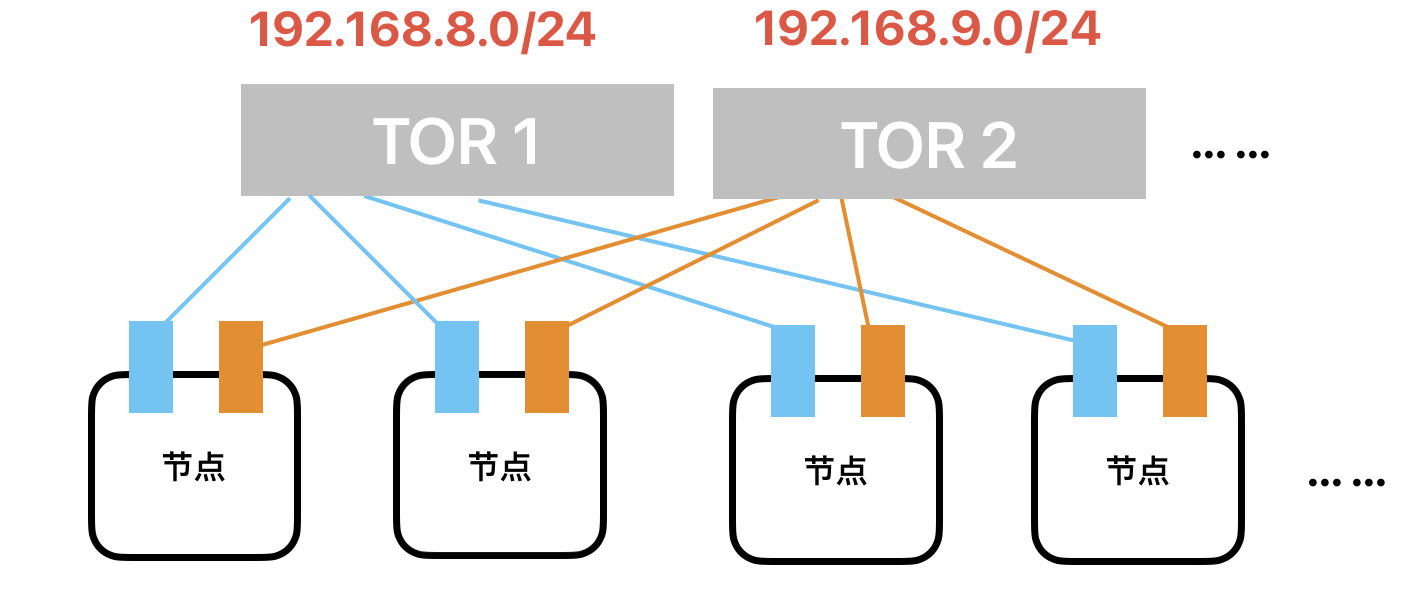
Kubernetes集群版本为1.25.7
部署
Nvidia Network Operator
整体方案是使用Nvidia Network Operator的SR-IOV部署模式,每张RDMA做4个VF。
为了保证VF之间的连通性,VF需要使用其PF的网段中的地址,比如一张RDMA网卡的地址是192.168.8.1,接在第一个tor下,则其四张VF需要从192.168.8.0/24剩余的IP中获取地址,才能进行通信。因此,会有两个子网,用于两类VF的IP分配。
临时方案是创建两套sr-iov的resource,分别对应两套networkattachmentdefinition,相对麻烦。后期可能会对IPAM组件进行修改,以实现根据PF选择subnet来分配VF的IP。
首先部署Nvidia Network Operator:
$ helm install -n nvidia-network-operator nvidia-network-operator network-operator-23.7.0.tgz -f value.yaml其中value.yaml如下所示:
# version: v23.7.0
# images:
# nvcr.io/nvidia/cloud-native/network-operator:v23.7.0
# nvcr.io/nvidia/mellanox/sriov-network-operator-config-daemon:network-operator-23.7.0
# nvcr.io/nvidia/mellanox/sriov-network-operator:network-operator-23.7.0
# ghcr.io/k8snetworkplumbingwg/sriov-network-device-plugin:7e7f979087286ee950bd5ebc89d8bbb6723fc625
# ghcr.io/k8snetworkplumbingwg/whereabouts:v0.6.1-amd64
# ghcr.io/k8snetworkplumbingwg/ib-sriov-cni:v1.0.3
# ghcr.io/k8snetworkplumbingwg/multus-cni:v3.9.3
# ghcr.io/k8snetworkplumbingwg/sriov-cni:v2.7.0
# ghcr.io/k8snetworkplumbingwg/network-resources-injector:v1.4
# ghcr.io/k8snetworkplumbingwg/sriov-network-operator-webhook:v1.1.0
# registry.k8s.io/nfd/node-feature-discovery:v0.13.2
# nvcr.io/nvidia/mellanox/mofed:23.07-0.5.0.0
# registry.paas/cmss/cloud-native/k8s-rdma-shared-dev-plugin:v1.3.2
nfd:
enabled: true
sriovNetworkOperator:
enabled: true
# inject additional values to nodeSelector for config daemon
configDaemonNodeSelectorExtra:
node-role.kubernetes.io/node: ""
# Node Feature discovery chart related values
node-feature-discovery:
image:
repository: registry.paas/cmss/node-feature-discovery
worker:
config:
sources:
pci:
deviceClassWhitelist:
- "0300"
- "0302"
# 添加0200类型(网卡)
- "0200"
deviceLabelFields:
- vendor
# SR-IOV Network Operator chart related values
sriov-network-operator:
# Image URIs for sriov-network-operator components
images:
operator: registry.paas/cmss/mellanox/sriov-network-operator:network-operator-23.7.0
sriovConfigDaemon: registry.paas/cmss/mellanox/sriov-network-operator-config-daemon:network-operator-23.7.0
sriovCni: registry.paas/cmss/sriov-cni:v2.7.0
ibSriovCni: registry.paas/cmss/ib-sriov-cni:v1.0.3
sriovDevicePlugin: registry.paas/cmss/sriov-network-device-plugin:7e7f979087286ee950bd5ebc89d8bbb6723fc625
resourcesInjector: registry.paas/cmss/network-resources-injector:v1.4
webhook: registry.paas/cmss/sriov-network-operator-webhook:v1.1.0
# imagePullSecrest for SR-IOV Network Operator related images
# imagePullSecrets: []
# General Operator related values
# The operator element allows to deploy network operator from an alternate location
operator:
repository: registry.paas/cmss/cloud-native
# NicClusterPolicy CR values:
deployCR: true
ofedDriver:
deploy: false
repository: registry.paas/cmss/mellanox
rdmaSharedDevicePlugin:
deploy: false
image: k8s-rdma-shared-dev-plugin
repository: registry.paas/cmss/cloud-native
version: v1.3.2
resources:
- name: rdma_shared_device
deviceIDs: ["101b"]
rdmaHcaMax: 8
sriovDevicePlugin:
repository: registry.paas/cmss
deploy: false
resources:
- name: hostrdma
devices: ["101b"]
secondaryNetwork:
deploy: true
cniPlugins:
deploy: false
multus:
deploy: false
repository: registry.paas/cmss
image: multus-cni
version: v3.9.3
ipamPlugin:
deploy: true
repository: registry.paas/cmss相比官方的values.yaml,主要做了如下修改:
1、node-feature-discovery添加了0200类型,也就是网卡的类型。
2、替换了官方镜像,主要是替换镜像仓库地址。
3、未部署ofedDriver。RDMA网卡做SR-IOV需要ofed,但官方提供的ofedDriver镜像不支持环境里的操作系统,采用直接安装在节点的方式。
4、secondaryNetwork部分只部署了whereabouts。cniPlugins在部署Kubernetes集群的时候已经安装了,multus v3.9.3存在不支持 k8s 1.21的问题,而高版本multus的init方式发生改变,使用nvidia-network-policy无法部署。
部署Nvidia Network Operator后,会部署whereabouts/daemonset、sriov-network-config-daemon/daemonset、nvidia-network-operator-sriov-network-operator/deployment、nvidia-network-operator-node-feature-discovery以及nvidia-network-operator/deployment。其中sriov-network-config-daemon/daemonset以及后面的sriov-device-plugin如果没启动,一般是node的label不匹配的原因,比如我这里的sriov-network-config-daemon的nodeSelector如下所示:
$ kubectl get ds sriov-network-config-daemon -n nvidia-network-operator
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
sriov-network-config-daemon 128 128 128 128 128 beta.kubernetes.io/os=linux,network.nvidia.com/operator.mofed.wait=false,node-role.kubernetes.io/worker= 23h接下来部署multus,最新的tag是v4.0.2,部署后也会有个循环调用的问题,因此最终使用的tag是snapshot。部署yaml见官网,其中networkattachmentdefinition CRD应该是在Nvidia Network Operator部署sriov-network-operator的时候已经部署过了,因此,部署multus时会有个报错,不用管。
SriovNetworkNodePolicy
sriov-network-operator使用SriovNetworkNodePolicy CRD来同步sriov-device-plugin,使用SriovNetwork CRD来同步networkattachmentdefinition。具体逻辑如下,需要注意步骤6中会重启节点。
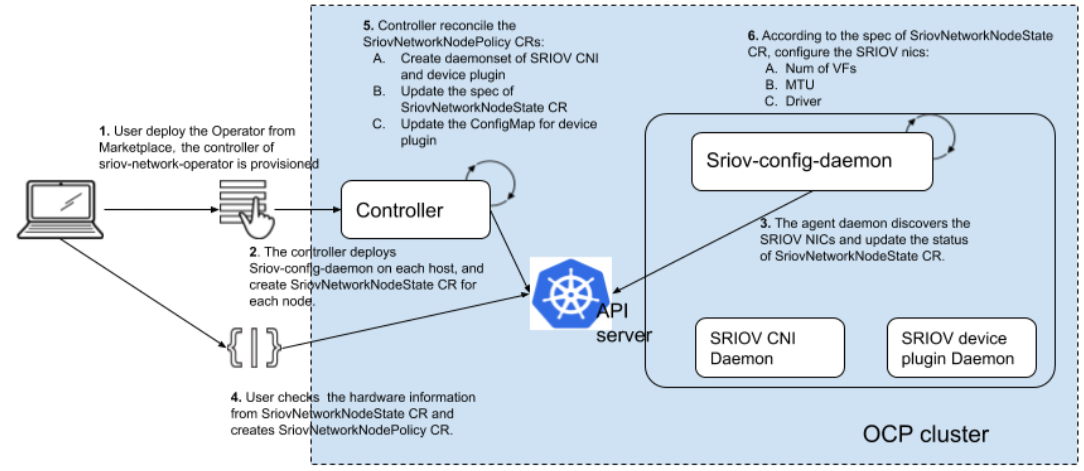
按照前面所说的,我们会部署两套SriovNetworkNodePolicy,一套用于纳管192.168.8.0/24这个tor下的网卡,另一套纳管192.168.9.0/24这个tor下的网卡。
创建两个SriovNetworkNodePolicy:
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: tor1
namespace: nvidia-network-operator
spec:
deviceType: netdevice
mtu: 1500
nicSelector:
pfNames: ["ens85np0"]
nodeSelector:
gpu-type: nvidia-a800
numVfs: 4
priority: 90
isRdma: true
resourceName: rdma_vf_tor1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: tor2
namespace: nvidia-network-operator
spec:
deviceType: netdevice
mtu: 1500
nicSelector:
pfNames: ["enp83s0np0"]
nodeSelector:
gpu-type: nvidia-a800
numVfs: 4
priority: 90
isRdma: true
resourceName: rdma_vf_tor2上面yaml中,分别通过pfNames对节点上的两张RDMA进行选择;部署的节点,使用gpu-type: nvidia-a800进行了选择,因为整个集群中还有其他异构的GPU;resourceName设置了最终device plugin上报的资源名称,这里第一个tor下的RDMA网卡虚出来的VF,被上报为rdma_vf_tor1,第二个tor的上报为rdma_vf_tor2。
创建完后,在nvidia-network-operator命名空间下会有相应的sriov-device-plugin容器启动,在nvidia-network-operator命名空间下通过查看device-plugin-config/configmap能看到每个节点都有两个resource。然后节点会被重启,用于配置vf。通过查询node的status,验证resource是否已正常上报。
$ kubectl get node xxx -o yaml | grep rdma_vf_tor
nvidia.com/rdma_vf_tor1: "4"
nvidia.com/rdma_vf_tor2: "4"NetworkAttachmentDefinition
接下来创建networkattachmentdefinition,之所以不使用SriovNetwork是因为环境中网卡众多,需要使用sbr cni在确保数据包能正确被转发。而SriovNetwork只能为sriov CNI配置ipam,而不是配置cni plugin链。
如果不使用
sbr,会出现下面的情况:
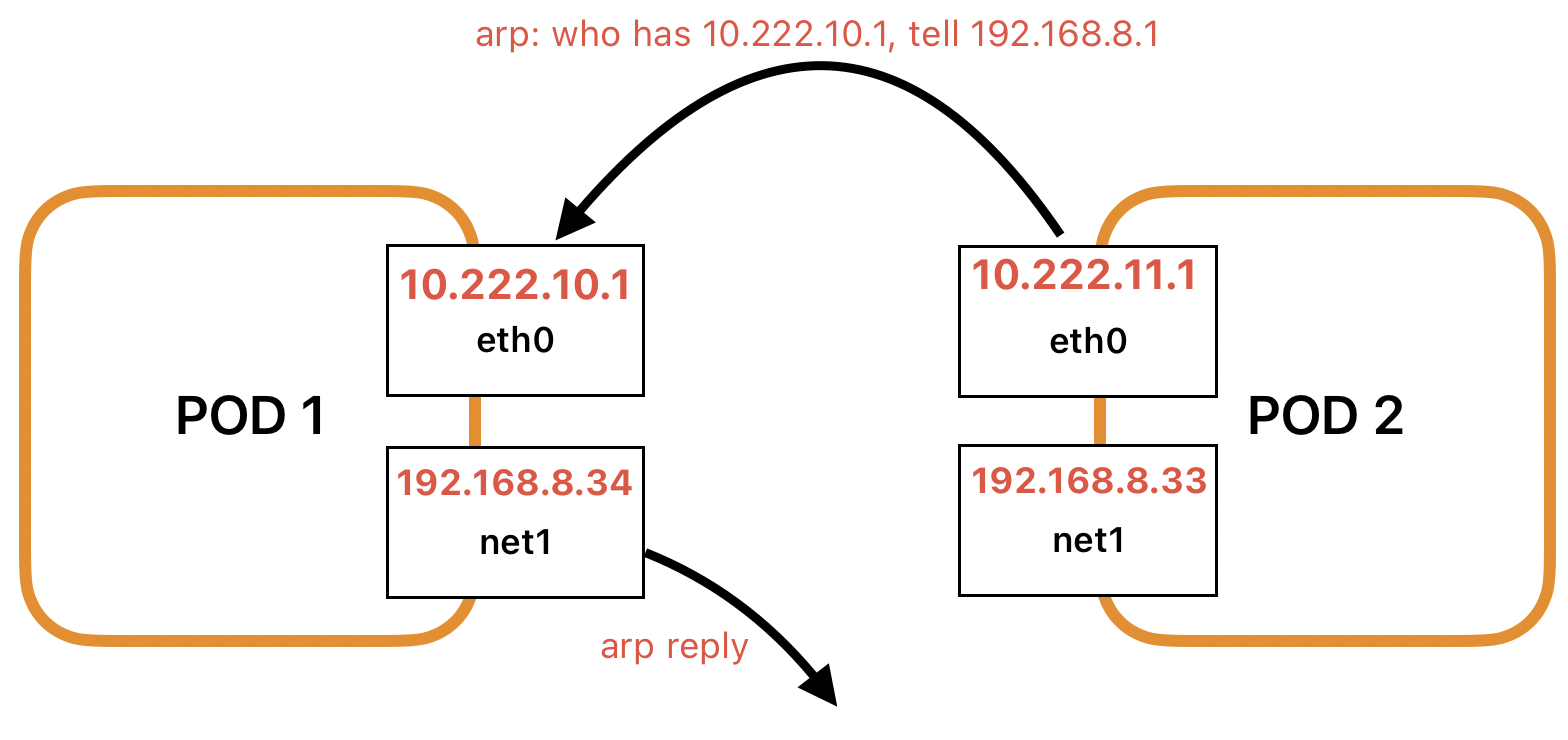
比如两个跨节点Pod,分别分配了容器网络(集群中使用的是Calico)以及RDMA网卡,如下图所示,其中eth0是Calico的网卡,net1是RDMA的VF网卡。
由于POD1上的路由规则如下所示,192.168.8.1是其宿主机上的RDMA网卡地址。
$ ip route get 10.222.10.1
10.222.10.1 dev cali0d555601df0 src 192.168.8.1 uid 0 cache导致当从Pod2中
pingPod1时,会出现who has 10.222.10.1, tell 192.168.8.1的arp请求,而pod里对于192.168.8.0/24这个网卡的路由是从net1发出,导致arp reply丢失,从而容器网络有问题。
创建如下的networkattachmentdefinition,其中192.168.8.0-32以及192.168.9.0-192.168.9.32已被节点使用,被排除在外。
---
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
annotations:
k8s.v1.cni.cncf.io/resourceName: nvidia.com/rdma_vf_tor1
name: rdma-tor1
namespace: default
spec:
config: |-
{
"cniVersion": "0.3.1",
"name": "rdma-tor1",
"plugins": [
{
"type": "sriov",
"vlan": 0,
"vlanQoS": 0,
"ipam": {
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"log_file": "/tmp/whereabouts.log",
"log_level": "debug",
"type": "whereabouts",
"range": "192.168.8.0/24",
"exclude": [
"192.168.8.0/27",
"192.168.8.32/32"
]
}
},
{
"type": "sbr"
}
]
}
---
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
annotations:
k8s.v1.cni.cncf.io/resourceName: nvidia.com/rdma_vf_tor2
name: rdma-tor2
namespace: default
spec:
config: |-
{
"cniVersion": "0.3.1",
"name": "rdma-tor2",
"plugins": [
{
"type": "sriov",
"vlan": 0,
"vlanQoS": 0,
"ipam": {
"datastore": "kubernetes",
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/whereabouts.d/whereabouts.kubeconfig"
},
"log_file": "/tmp/whereabouts.log",
"log_level": "debug",
"type": "whereabouts",
"range": "192.168.9.0/24",
"exclude": [
"192.168.9.0/27",
"192.168.9.32/32"
]
}
},
{
"type": "sbr"
}
]
}测试
接下来使用Pod测试分配与连通性。分别在两个节点上创建两个测试Pod,这里我们使用rdma_vf_tor1,rdma_vf_tor2的测试是一样的。
---
apiVersion: v1
kind: Pod
metadata:
name: rdma-test-pod1
annotations:
k8s.v1.cni.cncf.io/networks: rdma-tor1
spec:
restartPolicy: OnFailure
containers:
- image: registry.paas/cmss/rping-test:latest
name: rdma-test-pod
imagePullPolicy: IfNotPresent
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
requests:
nvidia.com/rdma_vf_tor1: 1
limits:
nvidia.com/rdma_vf_tor1: 1
command:
- sh
- -c
- |
ls -l /dev/infiniband /sys/class/infiniband /sys/class/net
sleep 1000000
---
apiVersion: v1
kind: Pod
metadata:
name: rdma-test-pod2
annotations:
k8s.v1.cni.cncf.io/networks: rdma-tor1
spec:
restartPolicy: OnFailure
containers:
- image: registry.paas/cmss/rping-test:latest
name: rdma-test-pod
imagePullPolicy: IfNotPresent
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
requests:
nvidia.com/rdma_vf_tor1: 1
limits:
nvidia.com/rdma_vf_tor1: 1
command:
- sh
- -c
- |
ls -l /dev/infiniband /sys/class/infiniband /sys/class/net
sleep 1000000创建成功后,在两个Pod里分别能看到eth0、net1两张网卡,net1分配192.168.8.0/24内的地址。
在一个Pod里启动服务:
# 启动一个 RDMA 服务
~# ib_read_lat在另一个Pod里访问服务:
# 访问对方 Pod 的服务,10.222.16.53是服务端Pod的calico网卡(eth0)地址
~# ib_read_lat 10.222.16.53对RoCE进行抓包
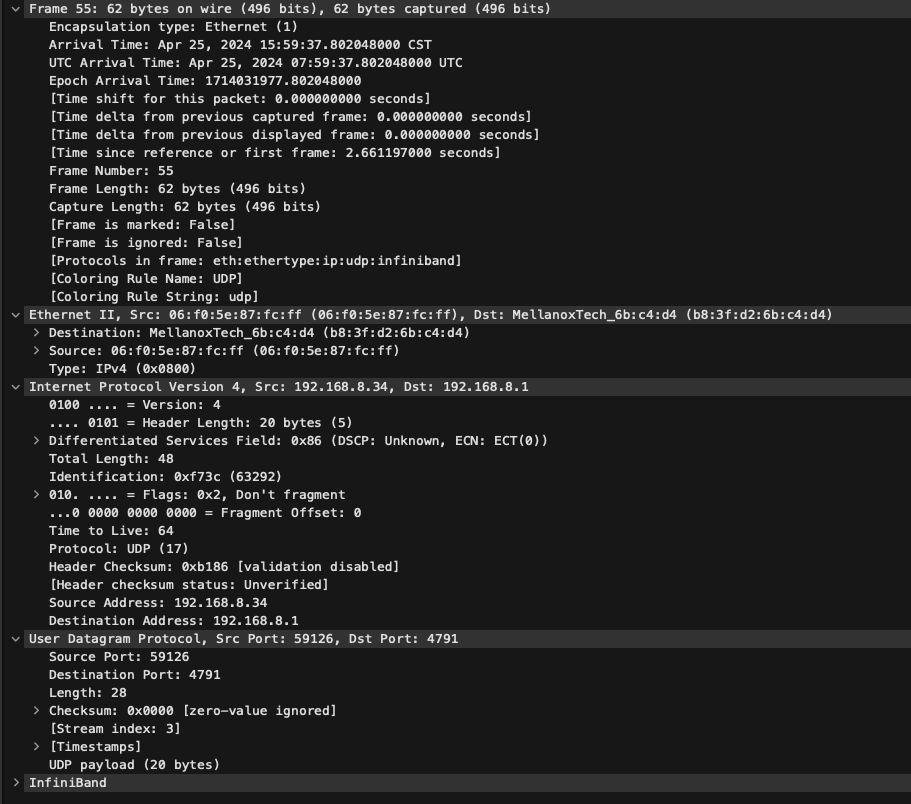
仍然使用上面的rdma-test-pod1、rdma-test-pod2,其中rdma-test-pod1中挂载的是mlx5_2,rdma-test-pod2挂载的是mlx5_5。
首先确定RoCE模式是RoCE V2,RoCE V2使用的UDP进行封装,RoCE V1使用以太网数据包进行封装。
$ cma_roce_mode -d mlx5_2 -p 1
RoCE V2
// 如果显示IB/RoCE V1,通过cma_roce_mode -d mlx5_2 -p 1 -m 2来修改接着在rdma-test-pod1所在的节点上运行一个mellanox/tcpdump-rdma容器用于抓包,执行:
// 创建traces目录
$ mkdir /tmp/traces
// 启动mellanox/tcpdump-rdma容器,执行tcpdump抓取mlx5_2的数据包
$ nerdctl run -it -v /dev/infiniband:/dev/infiniband -v /tmp/traces:/tmp/traces --net=host --privileged --rm registry.paas/cmss/tcpdump-rdma bash
tcpdump-rdma@/$ tcpdump -i mlx5_0 -s 0 -w /tmp/traces/roce.pcap接着在rdma-test-pod1容器中执行:
$ ib_write_bw -n 5 -q 1 -s 4096 -d mlx5_2 -R在rdma-test-pod2容器中执行:
$ ib_write_bw -n 5 -q 1 -s 4096 -d mlx5_5 10.222.16.53 -R测试完成后,可以在wire-shark里可以看到RoCE V2数据包。

其他方案
spidernet-io/spiderpool项目中有“基于SR-IOV隔离使用RDMA网卡“的方案,也是用于RoCE的场景,跟上面介绍的方案,不同之处在于做了dev的隔离,将RDMA子系统工作在exclusive模式,适合一个节点存在多个租户Pod的场景。由于我们的业务场景里,一个节点只属于一个租户,因此使用的share模式。